올해 5월에 서비스D에서 필요한 메뉴를 위해 진행한 프로젝트가 있었다.
구축은 되었는데 선행되어야 하는 시스템이 필요하다 보니 아직 실제 서비스에 배포되진 못했다.
나중에 다시 그 프로젝트를 손대야 할 날이 올 것 같아서
일단 진행하면서 기록했던 것들을(이전 블로그 글들) 이 블로그에 옮겨 놓으려고 글을 쓰게 되었다.
Python3, PyCharm 설치
운영체제: mac
mac에는 파이썬 2.X 버전이 기본적으로 설치되어 있다고 한다.
Python에 대해 잘 모르지만 찾아보니 Python3을 많이 쓰는 것 같아서 Python3과 PyCharm을 설치했다.
Python 설치: https://www.python.org/

PyCharm 설치: https://www.jetbrains.com/pycharm/

설치 후 새로운 프로젝트를 생성하면
Hi, PyCharm을 출력하는 프로젝트가 생성된다.
이렇게 설치를 마친 후, 스크래핑을 하기 위해 알아야 할 라이브러리인
pyautogui, requests, beautifulsoup, selenium에 대해 공부했다.
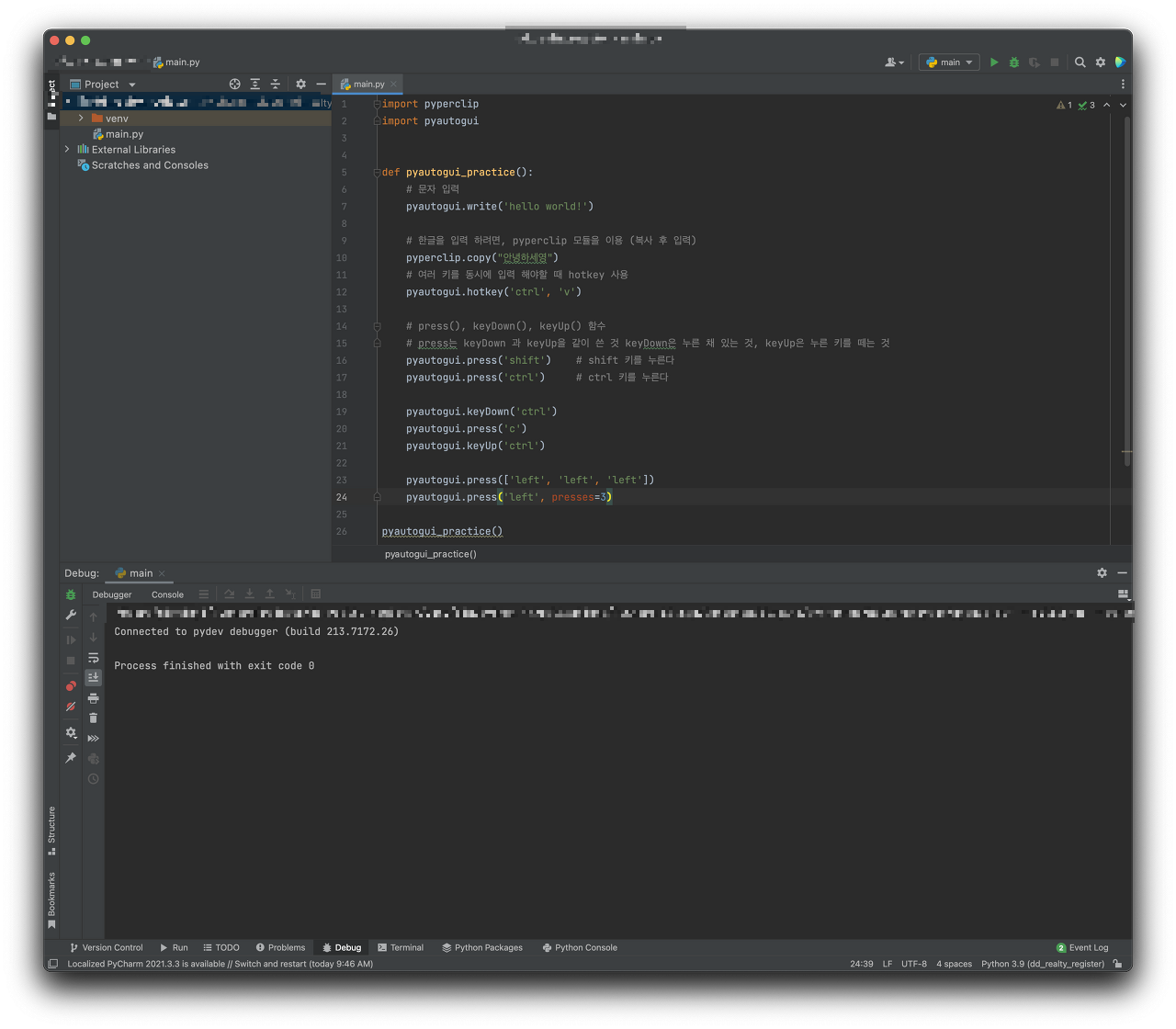
pyautogui 사용법
pyautogui란?
마우스와 키보드 제어를 도와주는 라이브러리이다.
설치 방법
pip install pyautogui마우스 제어 예제

키보드 제어 예제
requests, beautifulsoup, selenium 사용법
requests 사용법
requests 설치
pip install requests
URL 요청하기 - get
import requests
response = requests.get('https://www.naver.com/')
print(response.status_code)
print(response.text)200(status_code)와 HTML 코드 (text)를 프린트 한다
- 파라미터를 전달하는 방법
import requests
url = 'https://section.blog.naver.com/Search/Post.nhn?pageNo=1&rangeType=ALL&orderBy=sim&keyword=%ED%8C%8C%EC%9D%B4%EC%8D%AC'
params = {
'pageNo': 1,
'rangeType': 'All',
'orderBy': 'sim',
'keyword': '파이썬'
}
response = requests.get('https://section.blog.naver.com/Search/Post.nhn', params=params)
print(response.status_code)
print(response.text)네이버 블로그에 파라미터를 전달하는 것 같다
url은 왜 있는 건지 아직 잘 모르겠지만 아무튼!
BeautifulSoup 사용법
BeautifulSoup가 필요한 이유
request.text를 이용해 가져온 데이터는 텍스트 형태의 html이다.
텍스트 형태의 데이터에서 원하는 html태그를 추출할 수 있게 해주는 것이 BeautifulSoup이다.
즉, html을 수프 객체로 만들어서 추출하기 쉬벡 만들어준다.
BeautifulSoup 설치
pip install beautifulsoup4
BeautifulSoup 사용법
import requests
from bs4 import BeautifulSoup
url = 'https://kin.naver.com/search/list.nhn?query=%ED%8C%8C%EC%9D%B4%EC%8D%AC'
response = requests.get(url)
if response.status_code == 200:
html = response.text
soup = BeautifulSoup(html, 'html.parser')
print(soup)
else:
print(response.status_code)네이버 지식인에 파이썬을 검색한 url이 응답 코드가 200일때, html을 받아와서 soup 객체로 변환을 한다
네이버 지식인 크롤링 예제
네이버 지식인에 "파이썬"을 검색하면 첫 번째로 나오는 지식인의 제목을 가져오게 한다
1. https://kin.naver.com/search/list.nhn?query=%ED%8C%8C%EC%9D%B4%EC%8D%AC
파이썬 검색결과 : 네이버 지식iN
파이썬의 지식iN Q&A 검색결과입니다. 궁금증을 해결하지 못했다면 지식iN '질문하기'를 해보세요.
kin.naver.com
2. f12 (개발자 도구)를 누른다
3. 개발자도구에서 inspector를 클릭한 후 첫번째 제목을 클릭한다

4. 선택한 html 태그에서 우클릭 > Copy > Copy selector

5. soup.select_one을 이용해 html 요소를 찾을 수 있는데, css 선택자를 사용해서 찾을 수 있다. 복사한 css 선택자를 select_one의 함수 인자로 넣는다
import requests
from bs4 import BeautifulSoup
url = 'https://kin.naver.com/search/list.nhn?query=%ED%8C%8C%EC%9D%B4%EC%8D%AC'
response = requests.get(url)
if response.status_code == 200:
html = response.text
soup = BeautifulSoup(html, 'html.parser')
title = soup.select_one('#s_content > div.section > ul > li:nth-child(1) > dl > dt > a')
print(title)
else:
print(response.status_code)6. 텍스트만 뽑아오고 싶다면 get_text() 함수를 이용하면 된다.
print(title.get_text())7. 제목들을 뽑아오고 싶다면 다음과 같이 작성해주면 된다
import requests
from bs4 import BeautifulSoup
url = 'https://kin.naver.com/search/list.nhn?query=%ED%8C%8C%EC%9D%B4%EC%8D%AC'
response = requests.get(url)
if response.status_code == 200:
html = response.text
soup = BeautifulSoup(html, 'html.parser')
ul = soup.select_one('ul.basic1')
titles = ul.select('li > dl > dt > a')
for title in titles:
print(title.get_text())
else:
print(response.status_code)selenium 사용법
BeautifulSoup 라이브러리만으로도 다양한 사이트의 정보를 추출할 수 있다.
그런데 BeautifulSoup에는 "자바스크립트에서 동적으로 생성된 정보는 가져올 수 없다"라는 한계가 있다
Ajax 형태로 서버와 데이터를 주고 받아 화면에 뿌려주는 사이트가 많아졌는데 이러한 형식으로 데이터를 주고 받으면 url 변경이나 새로고침 없이 데이터를 가져오게 된다
그래서 selenium 라이브러리를 사용하는 이유는 다음과 같다.
1. 자바스크립트가 동적으로 만든 데이터를 크롤링 하기 위해
2. 사이트의 다양한 HTML 요소에 클릭, 키보드 입력 이벤트를 주기 위해
selenium을 잘 활용하면, 평소에 반복적으로 하고 있는 웹상의 업무를 자동화 할 수 있다.
1. 자동으로 로그인하기
2. 메일 보내기 자동화
3. 블로그 이웃 새글 자동 좋아요 누르기
4. 인스타그램 자동으로 좋아요, 댓글 작성하기
등등
selenium 모듈 설치
pip install selenium크롬 드라이버 설치
크롬 버전 확인 후 버전에 맞게 다운로드 한다

https://chromedriver.chromium.org/downloads
ChromeDriver - WebDriver for Chrome - Downloads
Current Releases If you are using Chrome version 101, please download ChromeDriver 101.0.4951.15 If you are using Chrome version 100, please download ChromeDriver 100.0.4896.60 If you are using Chrome version 99, please download ChromeDriver 99.0.4844.51 F
chromedriver.chromium.org
압축 해제 후 프로젝트 폴더에 넣어준다
selenium으로 크롬 브라우저 창 열기
from selenium import webdriver
driver = webdriver.Chrome(executable_path='./chromedriver')
url = 'https://www.google.com'
driver.get(url)이렇게 실행하면 아래와 같이 구글 창이 뜬다!
만약 경고 메세지가 나온다면 아래의 링크에 소개된 방식으로 코드를 작성하면 된다

실행했을 때 확인되지 않은 개발자의 Mac 앱 열기가 나온다면
설정 > 보안 및 개인 정보 보호 > 다음에서 다운로드 한 앱 허용에 모든 곳을 체크 해준다
만약, 모든 곳이 없다면
터미널에 sudo spctl --master-disable를 입력한 후 재시동을 해준다

Reference
'Python' 카테고리의 다른 글
| [pyautogui] click, keyDown, press not working, python 관리자 권한으로 실행 (0) | 2022.08.19 |
|---|---|
| [selenium] NoSuchElementException 해결 방법 (0) | 2022.08.19 |
| [selenium] cookie 설정 방법 (0) | 2022.08.19 |
| [selenium] no such element: Unable to locate element (0) | 2022.08.19 |
| [selenium] executable_path has been deprecated, please pass in a Service object (0) | 2022.08.19 |
올해 5월에 서비스D에서 필요한 메뉴를 위해 진행한 프로젝트가 있었다.
구축은 되었는데 선행되어야 하는 시스템이 필요하다 보니 아직 실제 서비스에 배포되진 못했다.
나중에 다시 그 프로젝트를 손대야 할 날이 올 것 같아서
일단 진행하면서 기록했던 것들을(이전 블로그 글들) 이 블로그에 옮겨 놓으려고 글을 쓰게 되었다.
Python3, PyCharm 설치
운영체제: mac
mac에는 파이썬 2.X 버전이 기본적으로 설치되어 있다고 한다.
Python에 대해 잘 모르지만 찾아보니 Python3을 많이 쓰는 것 같아서 Python3과 PyCharm을 설치했다.
Python 설치: https://www.python.org/
PyCharm 설치: https://www.jetbrains.com/pycharm/
설치 후 새로운 프로젝트를 생성하면
Hi, PyCharm을 출력하는 프로젝트가 생성된다.
이렇게 설치를 마친 후, 스크래핑을 하기 위해 알아야 할 라이브러리인
pyautogui, requests, beautifulsoup, selenium에 대해 공부했다.
pyautogui 사용법
pyautogui란?
마우스와 키보드 제어를 도와주는 라이브러리이다.
설치 방법
pip install pyautogui마우스 제어 예제
키보드 제어 예제
requests, beautifulsoup, selenium 사용법
requests 사용법
requests 설치
pip install requests
URL 요청하기 - get
import requests
response = requests.get('https://www.naver.com/')
print(response.status_code)
print(response.text)200(status_code)와 HTML 코드 (text)를 프린트 한다
- 파라미터를 전달하는 방법
import requests
url = 'https://section.blog.naver.com/Search/Post.nhn?pageNo=1&rangeType=ALL&orderBy=sim&keyword=%ED%8C%8C%EC%9D%B4%EC%8D%AC'
params = {
'pageNo': 1,
'rangeType': 'All',
'orderBy': 'sim',
'keyword': '파이썬'
}
response = requests.get('https://section.blog.naver.com/Search/Post.nhn', params=params)
print(response.status_code)
print(response.text)네이버 블로그에 파라미터를 전달하는 것 같다
url은 왜 있는 건지 아직 잘 모르겠지만 아무튼!
BeautifulSoup 사용법
BeautifulSoup가 필요한 이유
request.text를 이용해 가져온 데이터는 텍스트 형태의 html이다.
텍스트 형태의 데이터에서 원하는 html태그를 추출할 수 있게 해주는 것이 BeautifulSoup이다.
즉, html을 수프 객체로 만들어서 추출하기 쉬벡 만들어준다.
BeautifulSoup 설치
pip install beautifulsoup4
BeautifulSoup 사용법
import requests
from bs4 import BeautifulSoup
url = 'https://kin.naver.com/search/list.nhn?query=%ED%8C%8C%EC%9D%B4%EC%8D%AC'
response = requests.get(url)
if response.status_code == 200:
html = response.text
soup = BeautifulSoup(html, 'html.parser')
print(soup)
else:
print(response.status_code)네이버 지식인에 파이썬을 검색한 url이 응답 코드가 200일때, html을 받아와서 soup 객체로 변환을 한다
네이버 지식인 크롤링 예제
네이버 지식인에 "파이썬"을 검색하면 첫 번째로 나오는 지식인의 제목을 가져오게 한다
1. https://kin.naver.com/search/list.nhn?query=%ED%8C%8C%EC%9D%B4%EC%8D%AC
파이썬 검색결과 : 네이버 지식iN
파이썬의 지식iN Q&A 검색결과입니다. 궁금증을 해결하지 못했다면 지식iN '질문하기'를 해보세요.
kin.naver.com
2. f12 (개발자 도구)를 누른다
3. 개발자도구에서 inspector를 클릭한 후 첫번째 제목을 클릭한다
4. 선택한 html 태그에서 우클릭 > Copy > Copy selector
5. soup.select_one을 이용해 html 요소를 찾을 수 있는데, css 선택자를 사용해서 찾을 수 있다. 복사한 css 선택자를 select_one의 함수 인자로 넣는다
import requests
from bs4 import BeautifulSoup
url = 'https://kin.naver.com/search/list.nhn?query=%ED%8C%8C%EC%9D%B4%EC%8D%AC'
response = requests.get(url)
if response.status_code == 200:
html = response.text
soup = BeautifulSoup(html, 'html.parser')
title = soup.select_one('#s_content > div.section > ul > li:nth-child(1) > dl > dt > a')
print(title)
else:
print(response.status_code)6. 텍스트만 뽑아오고 싶다면 get_text() 함수를 이용하면 된다.
print(title.get_text())7. 제목들을 뽑아오고 싶다면 다음과 같이 작성해주면 된다
import requests
from bs4 import BeautifulSoup
url = 'https://kin.naver.com/search/list.nhn?query=%ED%8C%8C%EC%9D%B4%EC%8D%AC'
response = requests.get(url)
if response.status_code == 200:
html = response.text
soup = BeautifulSoup(html, 'html.parser')
ul = soup.select_one('ul.basic1')
titles = ul.select('li > dl > dt > a')
for title in titles:
print(title.get_text())
else:
print(response.status_code)selenium 사용법
BeautifulSoup 라이브러리만으로도 다양한 사이트의 정보를 추출할 수 있다.
그런데 BeautifulSoup에는 "자바스크립트에서 동적으로 생성된 정보는 가져올 수 없다"라는 한계가 있다
Ajax 형태로 서버와 데이터를 주고 받아 화면에 뿌려주는 사이트가 많아졌는데 이러한 형식으로 데이터를 주고 받으면 url 변경이나 새로고침 없이 데이터를 가져오게 된다
그래서 selenium 라이브러리를 사용하는 이유는 다음과 같다.
1. 자바스크립트가 동적으로 만든 데이터를 크롤링 하기 위해
2. 사이트의 다양한 HTML 요소에 클릭, 키보드 입력 이벤트를 주기 위해
selenium을 잘 활용하면, 평소에 반복적으로 하고 있는 웹상의 업무를 자동화 할 수 있다.
1. 자동으로 로그인하기
2. 메일 보내기 자동화
3. 블로그 이웃 새글 자동 좋아요 누르기
4. 인스타그램 자동으로 좋아요, 댓글 작성하기
등등
selenium 모듈 설치
pip install selenium크롬 드라이버 설치
크롬 버전 확인 후 버전에 맞게 다운로드 한다
https://chromedriver.chromium.org/downloads
ChromeDriver - WebDriver for Chrome - Downloads
Current Releases If you are using Chrome version 101, please download ChromeDriver 101.0.4951.15 If you are using Chrome version 100, please download ChromeDriver 100.0.4896.60 If you are using Chrome version 99, please download ChromeDriver 99.0.4844.51 F
chromedriver.chromium.org
압축 해제 후 프로젝트 폴더에 넣어준다
selenium으로 크롬 브라우저 창 열기
from selenium import webdriver
driver = webdriver.Chrome(executable_path='./chromedriver')
url = 'https://www.google.com'
driver.get(url)이렇게 실행하면 아래와 같이 구글 창이 뜬다!
만약 경고 메세지가 나온다면 아래의 링크에 소개된 방식으로 코드를 작성하면 된다
실행했을 때 확인되지 않은 개발자의 Mac 앱 열기가 나온다면
설정 > 보안 및 개인 정보 보호 > 다음에서 다운로드 한 앱 허용에 모든 곳을 체크 해준다
만약, 모든 곳이 없다면
터미널에 sudo spctl --master-disable를 입력한 후 재시동을 해준다
Reference
'Python' 카테고리의 다른 글
| [pyautogui] click, keyDown, press not working, python 관리자 권한으로 실행 (0) | 2022.08.19 |
|---|---|
| [selenium] NoSuchElementException 해결 방법 (0) | 2022.08.19 |
| [selenium] cookie 설정 방법 (0) | 2022.08.19 |
| [selenium] no such element: Unable to locate element (0) | 2022.08.19 |
| [selenium] executable_path has been deprecated, please pass in a Service object (0) | 2022.08.19 |